
There is a new and interesting press release from the University of Warwick's School of Engineering and Centre for Predictive Modeling in the UK announced the publication of a Science Advances paper entitled "Machine learning unifies the modeling of materials and molecules." The paper is a result of a collaboration between the university's James Kermody Ph.D., and six other colleagues from Britain, Europe, and the US. It describes in a new algorithm that "can predict whether or not a candidate drug molecule will bind to a target protein with 99% accuracy," which would give the field of drug discovery a big boost.
If the algorithm is used in conjunction with medicinal chemistry, (1) we could see some intriguing changes in the drug discovery process, both in reducing discovery time and also enabling chemists to avoid dead ends - compounds that may seem to produce the desired effect, but upon closer examination are just artifacts. Since drug discovery is one of the most difficult jobs the world we'll take any help we can get. But, will it really make a difference?
The paper is very technical (mostly math) and requires a knowledge of quantum mechanics, easily the most hideous subject ever invented. It is more or less incomprehensible (emphasis on more) from beginning to end. But, in its simplest form, the authors use mathematical models to calculate the properties of proteins and drugs at the atomic level. But just in case you like this stuff, here are some simple equations from the paper.

Does anyone really understand this??? Really??? Adapted from ScienceAdvances
This permits them to predict how a protein will fit together with the ligand (the drug that will bind to it). The algorithm is described as "machine-learning." As it acquires more data about how given molecules and proteins fit together, it becomes more adept at predicting how well other proteins will bind to other small molecules (the drugs).
This raises a few interesting questions. First, (and most important) will the method be robust enough to handle the huge number and variety of proteins that comprise pharmaceutical targets? Second, will the algorithm come up with chemical structures that may fit the protein target well, but be impossible or very difficult to synthesize? But most important, will the discovery, no matter how perfect it is, result in a paradigm shift in how drugs are discovered? This is where I am skeptical. Because of time and timing.
The study of the binding of drugs to a given target (receptor, enzyme...) and observation of a subsequent pharmacological response is the essence of drug discovery. Getting an experimental drug to find and impact a target is plenty hard enough. But doing this without also "hitting" other targets is even tougher. When drugs hit multiple targets they will often cause side effects. The property of hitting on the desired targets, which is called selectivity, is one of the biggest challenges of drug discovery. (2)
In general, a drug that acts selectively at its target will be safer than one that binds at multiple sites. But not always. Sometimes side effects are a result of the drug binding at the desired receptor and eliciting multiple responses, some of them unwanted. (This is called on-target toxicity, aka mechanism-based toxicity. It is a serious pain in the ass, and it has been the demise of many projects.)
The biggest impact of Kermode's algorithm will be decreasing the amount of time it takes to conduct high throughput screening (HTS), which is a standard technique that is used at the onset of many programs. HTS has arguably been the most useful method in discovering drugs, although computer-assisted-drug-design, CADD, people may take issue with this (3). Testing a very large numbers of chemical compounds is a huge job, but it isn't as bad as you'd think. Large collections of chemical compounds can be either purchased or are already be on hand at the company. Whenever chemists synthesize a chemical compound that is new to the company, a small sample is removed and gets submitted to a compound storage room. They are then dissolved, diluted and "given" to robots, which do the testing. It is an empirical approach and serendipity is always helpful. For example, A group of chemical compounds that were found to be useless for Program X may later be found to be a great starting point for Program Y. This is very common.
A little on how HTS fits into the process of drug discovery. HTS is an automated method for testing huge numbers of chemical compounds to determine whether any of them may have properties that would indicate that they may possess some sort of activity that would treat a disease or infection. HTS is a very early component of the drug discovery process. Here is a very brief summary of how it fits in.
The typical starting point in drug discovery is the selection of a disease or disease area (4). Then biologists determine which target or targets to pursue, based on the likelihood that hitting that target would have an impact on a particular disease or condition (5). Then they have to figure out how to set up a test for a whole bunch of different chemical compounds, and in an automated fashion. Hundreds of thousands (even millions) of different chemical compounds are run through the automated screen, which is done by sophisticated robots (6).

Part of an HTS apparatus. Photo: Technology Networks
Data are then generated on each chemical compound, and this information is used to determine if there is a chemical compound (better: a class of related compounds) that does whatever you want it to do, for example blocking the action of an enzyme that stops a virus from replicating. The amount of data are this point is enormous. An algorithm that could accurately predict in advance which chemicals will interact with a given protein targets would save an enormous amount of time and effort by eliminating compounds that will not hit the desired target. This sounds great, and you might think that this would drastically impact the speed of new drug discovery, but it can only do so much. The reason for this can be seen in Figure 1.
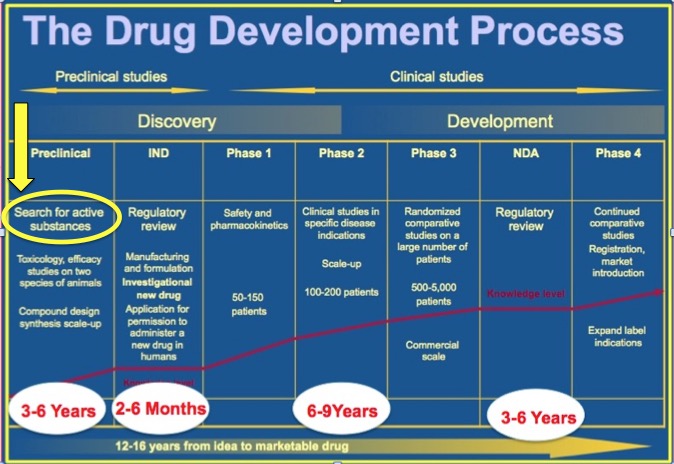
Figure 1. The timeline of stages in the development of a drug. Courtesy of Steve Schow, Ph.D.
The stage that Kermode's algorithm would be used is shown in the yellow circle above. Look where it is on the timeline - at the very beginning of the first of 7 stages that comprise the drug discovery process - preclinical research. The "search for active substances" normally takes a year or two, but even when you have them in hand, the work is just starting. Whatever compounds "light up" a test are hardly ever good enough to become drugs. Chemists have to optimize the activity and physical properties of the HTS "hits," which requires the synthesis of hundreds (sometimes thousands) of analogs. Then, process chemists have to figure out how to make the particular compound(s) on a large scale. Scientists who specialize in other areas, such as oral absorption, metabolism and toxicology need to study the compounds to determine whether or not they have suitable properties for drugs.
Then it gets difficult. Is there a suitable animal model to predict whether an experimental drug will work in humans? How toxic will it be in safety animal studies? Will the molecule be stable long enough to get to the target? If it is metabolized are the metabolites toxic even though the drug itself may not be?
I'm just scratching the surface of a very large set of issues that combine to make drug discovery so difficult. Even with the best possible predictive models of what compounds will do what, this is just one of the many hurdles that a drug faces before (IF) it gets to the pharmacy.
Kermode's algorithm is clever and could make the process a bit easier assuming that it holds up in "real life." But, as you can see in Figure 1 there is a lot more involved in discovering a drug. Despite all the modern technology we now use it is still a long shot to get from the lab to the drug store.
NOTES:
(1) The term "medicinal chemistry" is a bit confusing. We do not perform chemistry on known medicines as the name implies. Rather, we take our primary skill set (almost always synthetic organic chemistry) and combine it with biological and pharmacological information to design and synthesize molecules that we suspect may have the potency, low toxicity, metabolism, oral absorption ..... (many other properties) to be tested in humans. It is by nature a plodding and frustrating exercise. Even when it succeeds (rarely) it will take about 14 years to get something from your laboratory to the pharmacy.
(2) Prednisone is an example of a "dirty" drug. It interacts with multiple receptors in the body and has a long list of side effects, some of which are very bad. (See: Prednisone: Satan's Little Helper)
(3) At the risk of alienating what few friends I have left, CADD people are often mutants. Just a personal opinion. Nothing personal.
(4) The decision of what disease area(s) will be researched in a given drug company is based on company expertise in the area, financial and marketing considerations, and medical need. (Virtually every drug company had an HIV program running by the 1990s. The medical need was so great.)
(5) An HTS screen usually takes about a month, depending on the number of compounds being tested and complexity of the test.
(6) The fundamental biology behind the discovery of these targets is most frequently done in government and academic labs, although companies have this capability as well.

Josh Bloom
Director of Chemical and Pharmaceutical Science
Dr. Josh Bloom, the Director of Chemical and Pharmaceutical Science, comes from the world of drug discovery, where he did research for more than 20 years. He holds a Ph.D. in chemistry.


